QueryStar 🌟 + LlamaIndex 🦙: Slack Bot that Understands Your Data

Acknowledgement: >Thanks to Yi Ding (Head of Typescript and DevRel @LlamaIndex) and Caroline Frasca (Lu) (Senior Developer Experience Manager @Streamlit) for proofreading! >This tutorial is inspired by Build a chatbot with custom data sources, powered by LlamaIndex by
StreamlitandLlamaIndexteams.
Objective
Learn how to build a Slack bot that can answer questions about your own documents.
Usefulness: ⭐⭐⭐⭐⭐ | Difficulty Level: ⭐⭐
About the Slack Bot
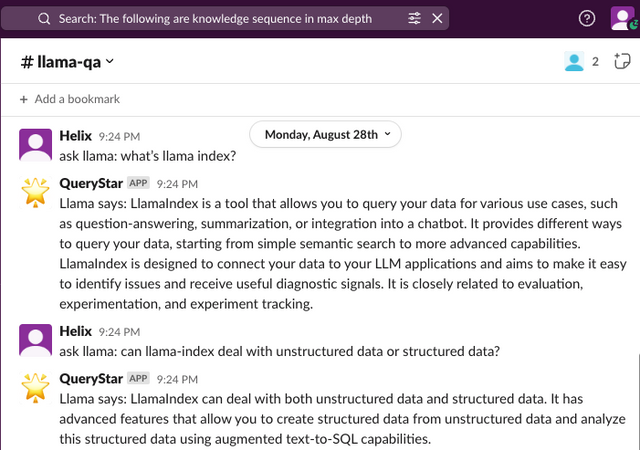
This bot helps Slack users learn about a new open-source project, called LlamaIndex. It "learns" from the project documentation and can answer questions about it.
Use Case Example
When a user posts a message (starting with "ask llama") to #ask-llama channel in a Slack workspace:
"ask llama: what's LlamaIndex?"
The bot sends a legit answer back to the channel:
Llama says: LlamaIndex is a tool that allows you to query your data for various use cases, such as question-answering, summarization, or integration into a chatbot.
Module Design
- AI (LLM) Function: After getting a question, this function should generate an answer that aligns with the context provided in the given documents.
- Trigger - Action:
- The bot should respond to messages that:
- are sent to a designated channel, AND
- contain trigger word "ask llama".
- The bot should extract user questions from the trigger messages, and run the LLM function to generate answers.
- The bot should post the answers back to the channel. Then, wait for future trigger events.
- The bot should respond to messages that:
Tech Stack
We want to maximize speed of learning and shipping, while leaving enough room for customization. Here, we choose the LOQ stack (LlamaIndex + OpenAI + Querystar), which allows us to make a fully functioning bot in less than one hour. Let's introduce the stack by module.
LlamaIndex for the LLM Function
The key capability of the function is to process documents and retrieve relevant context. We will implement this function using Retrieval Augmented Generation (RAG). The basic concepts of RAG are explained in Section 1: Some Basics.
LlamaIndex and OpenAI's LLMs give us great results with the least amount of code. The details are in Section 2: Data Indexing.
If you want to skip Section 1 and 2: this Jupyter notebook shows how the AI function is implemented.
QueryStar for the Bot
This module determines the bot's behavior, and provides an intuitive interface for humans to use AI.
QueryStar is used here to implement the design, with only 2 simple function calls. See details in Section 3: Bot development).
For those who are curious: this app.py file (24 lines of Python code) is all we need to ship the bot.
RAG Basics
When dealing with questions, we often need some reference materials to help to find answers. In this process, we retrieve paragraphs/context that are relevant to the questions.
A big challenge we will be facing if we want a computer program to do this:
how to quantify and mathematically measure relevance between any two pieces of information in the format of human language.
We must find a mathematical representation of text (words, sentences and paragraphs), and construct a measurement (as a proxy to relevance) among the representations.
A technique, called embedding, is widely adopted to transform texts into vectors. With embedding vectors, we can use the distance between them to quantify relevance.
A basic Retrieval Augmented Generation (RAG) algorithm can be implemented through the following steps:
- For any document, we divide the content into chunks, e.g., every 3 sentences, or every 100 words. Let's say we have 500 chunks after this step.
- We create
embeddingsfor each chunk, which gives us 500 "context vectors". - With any given question, we can get its embedding as well, which gives us one "question vector".
- Use the question vector to compare with the 500 context vectors, and select top N (e.g. 5) most similar ones. Then we believe those 5 are the most relevant to the question.
- We put the top 5 relevant text chunks in a prompt along with the question, and ask the LLM to "answer it only based on the given context, not other prior knowledge."
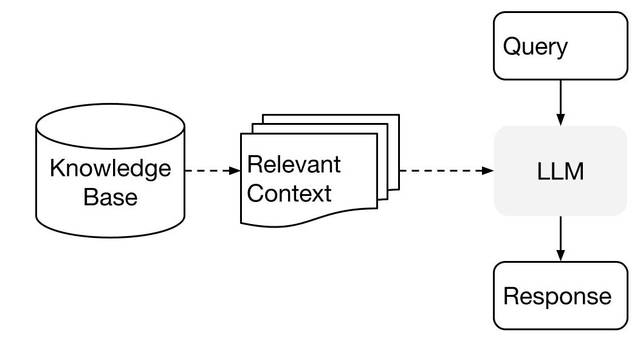
Image Source: LlamaIndex Docs
In contrast to solely sending the question to LLMs for query, RAG sends both question and relevant context, which can help to reduce hallucinations and improve accuracy.
However, implementing all 5 steps from scratch is not a simple task. This is where LlamaIndex comes in handy. It allows us to build a RAG pipeline with a few function calls.
What makes LlamaIndex more appealing to experienced engineers is that it provides many low-level APIs as well for customization.
Interested in giving it a try? Let's dive into the coding process.
RAG Function

Prep: Data Cleaning
Let's start with downloading/cloning LlamaIndex's doc folder to a local folder ask_llamaindex_slack_bot.
There are many types of files in the folder. Some filetypes (like .py or .bat) do not contain too much context. So, we only want to keep .md and .rst files:
# Data cleaning
dir_path = './lidocs' #local folder of LlamaIndex documentations
for root, dirs, files in os.walk(dir_path):
for file in files:
if file.endswith(('.md', '.rst')):
continue
else:
file_path = os.path.join(root, file)
os.remove(file_path)
Once the doc folder is clean, it's very convenient to use SimpleDirectoryReader function to load the entire folder to the lidocs object at once.
from llama_index import SimpleDirectoryReader
reader = SimpleDirectoryReader(input_dir="./lidocs", recursive=True)
lidocs = reader.load_data()
Prep: Document Indexing
Now we're ready to build the index by dividing each document into chunks and embedding them. LlamaIndex has a great API for this: VectorStoreIndex.from_documents(). Then we store index in files.
import openai
from llama_index import VectorStoreIndex
openai.api_key = os.getenv('OPENAI_API_KEY')
index = VectorStoreIndex.from_documents(lidocs)
# save index to files
index.storage_context.persist()
The storage folder automatically appears:
├── ask_llamaindex_slack_bot
│ ├── storage
│ │ ├── docstore.json
│ │ ├── graph_store.json
│ │ ├── index_store.json
│ │ └── vector_store.json
All the embedding vectors are saved in vector_store.json. The file is 33 MB and contains a mathematical representation of the LlamaIndex's entire documentation.
In this step, we use GPT, a commercial model service by OpenAI.
- Before building the index, make sure you have an OpenAI API key. This step may cost you up to $1 for GPT tokens. To avoid the cost, you can skip this step and download the
storagefolder from QueryStar demo repo. VectorStoreIndex.from_documents()call may take 2-5 mins to finish, highly depending on API latency in your region. :::
Function Development
With the index file in place, we can finally build the RAG function. Again, it's simple with LlamaIndex. We just need to load them to the index object, and use the built-in query engine to get a response:
def ask_llamaindex(question: str):
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# load index
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query(question)
return response
Now, let's build the bot!
Trigger-Action Based Slack Bot

Prep: QueryStar Setup
QueryStar is a low code Python package to simplify Trigger-Action based bot development. It shares the same design philosophy behind Streamlit, PyWebIO, Gradio, and Greppo: making it super easy for data teams and Python developers to ship interfaces between human and AI/data. These four projects are used for web UI, while Querystar is intended for bot development (more on this in the introduce).
Before running any code in this module, please make sure you already got a QueryStar token, installed the library, and can run the hello world slackbot. The setup process should only take you less than 10 mins.
QueryStar automatically integrate 3rd party API services which also include Slack authorization, so we do NOT need a Slack token here.
QueryStar token is free for one Slack workspace connection and unlimited bots in that workspace. :::
Prep: Creating app.py
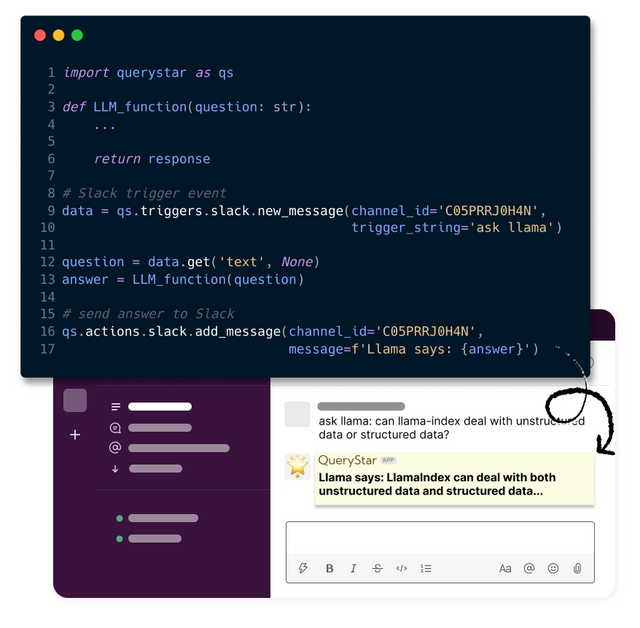
With QueryStar, a bot can be developed out of a single .py file. Let's create a file called app.py in ask_llamaindex_slack_bot folder, import some packages, and copy the ask_llamaindex() function here.
# app.py
import querystar as qs
from llama_index import StorageContext, load_index_from_storage
import os, openai
openai.api_key = os.getenv('OPENAI_API_KEY')
def ask_llamaindex(question: str):
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# load index
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query(question)
return response
new_message() Trigger
Let's recap how we designed the trigger in the beginning of the tutorial:
- The bot should respond to messages that:
- are sent to a designated channel, AND
- contain trigger word "ask llama".
This Slack message trigger can be easily done with triggers.slack.new_message() function:
data = qs.triggers.slack.new_message(channel_id='C05PRRJ0H4N', # channel: llama-qa
trigger_string='ask llama')
This script is quite self-explanatory. The bot is set to listen to new Slack messages. When a message matches the filter condition (channel_id AND trigger_string), a JSON object of the message will return to variable data.
An example message object (click to expand)
{
"client_msg_id":"...",
"type":"message",
"text":"ask llama: ...",
"user":"useid...",
"ts":"1693582549.746649",
"blocks":[...],
"team":"...",
"thread_ts":"1693536314.270179",
"parent_user_id":"...",
"channel":"C05PRRJ0H4N",
"event_ts":"1693582549.746649",
"channel_type":"group"
}
add_message() Action
This is what we designed for the actions:
- The bot should extract the user's question from the trigger message and run the LLM function to generate an answer.
- The bot should post the answer back to the channel. Then, wait for future trigger events.
Let's do it:
question = data.get('text', None)
answer = ask_llamaindex(question)
# send answer to Slack
qs.actions.slack.add_message(channel_id='C05PRRJ0H4N', text=f'Llama says: {answer}')
We first parse the trigger message to get question, which will be passed to ask_llamaindex() to generate an answer. Then, we use actions.slack.add_message() to post the answer back to the same channel.
That's all!
End-to-end Test
Open your terminal and run this command in ask_llamaindex_slack_bot folder:
$ querystar run app.py
Go to Slack and post a trigger message. It works 🤩🤩🤩 Now, you can invite your entire team to join this channel and learn LlamaIndex together!